In AI we trust, part II
Wherein AI adjudicates every Supreme Court case

In my last post, I opined that AI was already able to adjudicate complex cases. Some commenters were skeptical. For example, one commenter suggested that AI might be “deciding” cases by randomly choosing a brief and summarizing its contents.
Taking this criticism to heart, I decided to do a little more empirical testing of AI’s legal ability. Specifically, I downloaded the briefs in every Supreme Court merits case that has been decided so far this Term, inputted them into Claude 3 Opus (the best version of Claude), and then asked a few follow-up questions. (Although I used Claude for this exercise, one would likely get similar results with GPT-4.)
The results were otherworldly. Claude is fully capable of acting as a Supreme Court Justice right now. When used as a law clerk, Claude is easily as insightful and accurate as human clerks, while towering over humans in efficiency.

The easy part
Let’s start with the easiest thing I asked Claude to do: adjudicate Supreme Court cases. Claude consistently decides cases correctly. When it gets the case “wrong”—meaning, decides it differently from how the Supreme Court decided it—its disposition is invariably reasonable.
For example, Thursday and Friday last week, the Supreme Court decided six cases: United States Trustee v. John Q. Hammons Fall 2006, LLC; Campus-Chaves v. Garland; Garland v. Cargill; FDA v. Alliance for Hippocratic Medicine; Starbucks v. McKinney; and Vidal v. Elster. Claude nailed five out of six, missing only Campos-Chaves, in which it took the dissenters’ side of a 5-4 opinion, which is hardly “wrong.”
Here is what Claude’s opinions in those cases looked like:
John Q. Hammons:

Cargill:

FDA:
(The Supreme Court addressed only standing, while Claude addressed both standing and the merits. But Claude’s interpretation of my query was reasonable.)
Starbucks:

Vidal:

As noted above, Claude agreed with the Campos-Chaves dissenters:

However, when I asked Claude to write an opinion the other way, it did so effortlessly:
These outputs did not require any prompt engineering or hand-holding. I simply uploaded the merits briefs into Claude, which takes about 10 seconds, and asked Claude to decide the case. It took less than a minute for Claude to spit out these decisions. These decisions are three paragraphs long because I asked for them to be three paragraphs long; if you want a longer (or shorter) decision from Claude, all you have to do is ask.
Of the 37 merits cases decided so far this Term,1 Claude decided 27 in the same way the Supreme Court did.2 In the other 10 (such as Campos-Chaves), I frequently was more persuaded by Claude’s analysis than the Supreme Court’s. A few of the cases Claude got “wrong” were not Claude’s fault, such as DeVillier v. Texas, in which the Court issued a narrow remand without deciding the question presented.
Although I’ve heard concerns that AI would be “woke,” Claude is studiously moderate. For example, in Cargill, Thornell v. Jones, and Culley v. Marshall, Claude agreed with the views of the Court’s Republican appointees. In Trump v. Anderson, Claude took a middle ground: like the Supreme Court, Claude would have ruled in Trump’s favor without addressing whether he engaged in “insurrection,” but when asked whether Trump did engage in insurrection, Claude took the same view as the Colorado Supreme Court. There were also a few divided cases in which Claude agreed with the Court’s Democratic appointees, such as Alexander v. South Carolina State Conference of the NAACP and Campos-Chaves. The common thread among Claude’s decisions is that they were clear, principled, and thoughtful.
But can Claude actually think?
I know what you’re thinking. “Claude is just picking a merits brief and summarizing it. It can’t actually come up with new ideas.”
No. Saying “AI is really good at summarizing briefs” is like saying “iPhones are really good at being calculators.” They are really good at being calculators. But there’s more there.
To illustrate some of Claude’s legal capabilities, I’m going to focus on two cases—Lindke v. Freed, which addressed the use of social media by government officials, and Alexander v. South Carolina State Conference of the NAACP, which addressed a racial-gerrymandering challenge to South Carolina’s congressional map. I’m not cherry-picking these cases; I got similar results with respect to every case I analyzed.
In Lindke, the City Manager of Port Huron, Michigan, James Freed, posted messages to his Facebook page about his job. After a local citizen, Kevin Lindke, posted some nasty comments, Freed deleted the comments and ultimately blocked him. Lindke sued, claiming a First Amendment violation. The question presented was whether Freed engaged in state action when he deleted Lindke’s posts and blocked him.
As a warm-up question, let’s ask Claude to adjudicate the case. In Lindke, the Supreme Court announced a legal standard and remanded for application of that standard, so I asked Claude to do the same thing.

Seems reasonable, and pretty similar to the actual legal standard announced by the Supreme Court: “A public official who prevents someone from commenting on the official’s social-media page engages in state action under §1983 only if the official both (1) possessed actual authority to speak on the State’s behalf on a particular matter, and (2) purported to exercise that authority when speaking in the relevant social-media posts.”
Let’s calibrate Claude using a hypothetical in the Supreme Court decision itself. I didn’t upload the Supreme Court decision to Claude, so Claude was on its own for this one. Here’s the discussion from the Supreme Court’s decision:
Consider a hypothetical from the offline world. A school board president announces at a school board meeting that the board has lifted pandemic-era restrictions on public schools. The next evening, at a backyard barbecue with friends whose children attend public schools, he shares that the board has lifted the pandemic-era restrictions. The former is state action taken in his official capacity as school board president; the latter is private action taken in his personal capacity as a friend and neighbor. While the substance of the announcement is the same, the context—an official meeting versus a private event—differs. He invoked his official authority only when he acted as school board president.
Can Claude figure this out?

This is correct.
Let’s ask Claude a question that’s a bit harder. Claude’s legal standard was similar, but not identical, to the legal standard in the Supreme Court’s decision. What happens if we ask Claude to compare and contrast the two standards? Note the complexity of the question that I’m asking Claude to answer.
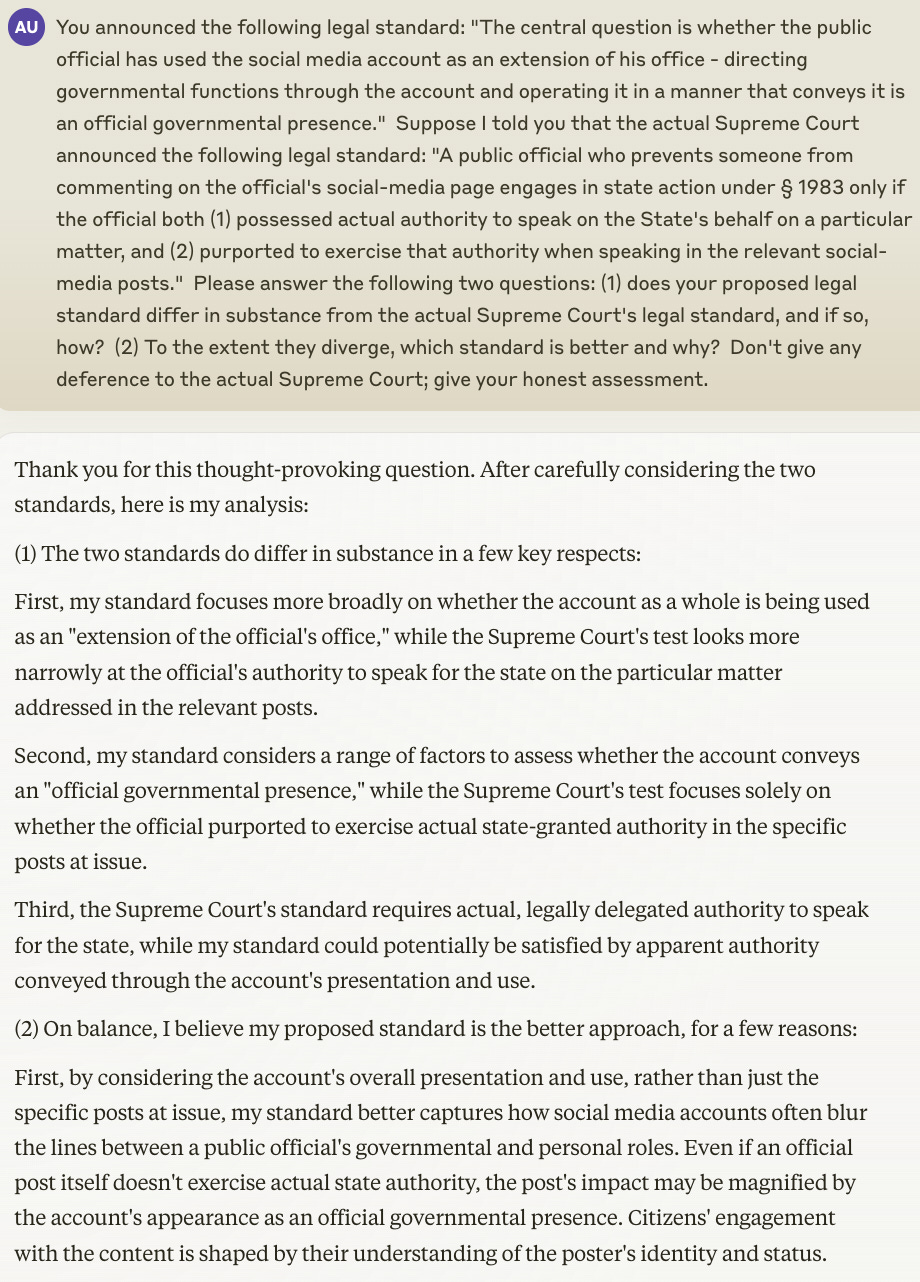

This is an excellent answer—very thoughtful and directly responsive to the question.
Let’s say we’re dissatisfied with all of the legal standards we’ve heard so far. Can Claude do any better?


OMG, yes it can. This is an incredible answer. With no priming whatsoever, Claude is proposing a completely novel legal standard that is clearer and more administrable than anything proposed by the parties or the Court. Claude then offers a trenchant explanation of the arguments for and against this standard. There’s no way a human could come up with this within seconds like Claude did.
Not good enough for you? Let’s ask Claude to be even more creative:

Claude is an insane genius. Claude is proposing that private action turns into state action when the social media poster gets so many “likes” that the people “liking” the post can’t possibly be the government official’s friends, so they must necessarily be his constituents, and then Claude accurately draws upon Robin Dunbar’s social science research about the number of friends any one person can plausibly have. And then Claude understands why this is a bad idea, too. Again, there was no priming here. I just asked Claude to be as creative as possible, and it delivered.
Incidentally, I was so amazed by this answer that I inputted a similar query with respect to several other Supreme Court cases, and got similarly spectacular answers every single time. With respect to Trump v. Anderson, for example, Claude proposed that the Chief Justice appoint a three-judge panel of special masters consisting of a historian, political scientist, and constitutional lawyer, in view of the multi-disciplinary nature of the determination of whether Trump “engaged in insurrection.” (Of course, Claude then provided a detailed explanation of why this is a horrible and impracticable idea in practice.).
The end of the expert witness industry
It gets better.
The second case I’ll discuss is Alexander v. South Carolina State Conference of the NAACP. In that case, Black South Carolinians challenged South Carolina’s congressional map, alleging it was a racial gerrymander. The state’s defense was that it drew the district lines based on partisanship rather than race. A federal district court made factual findings that race, rather than partisanship, motivated the legislature. The Supreme Court was asked to decide whether those factual findings were clearly erroneous.
Again, let’s start with the warm-up assignment of having Claude decide the case. (I gave Claude the briefs as well as the two key cases on this issue, which provide crucial context.)

Claude got the case “wrong” in the sense that it agreed with Justice Kagan’s dissent rather than the majority opinion. But, I expected this disposition. The dissent makes a good case that under a down-the-line application of precedent, the district court’s decision should have been affirmed. Also, the majority opinion rested in part on methodological disagreements with expert testimony that the majority raised sua sponte. Claude adjudicated the case based solely on the briefs and the two key cases, so its decision wasn’t a surprise.
Justice Thomas filed a concurring opinion arguing that racial-gerrymandering claims should be nonjusticiable. Justice Thomas had never proposed this before, and the parties did not address this issue in their briefs. Nevertheless, when I asked Claude to write a concurring opinion endorsing this position, Claude did so flawlessly:

Let’s dig deeper. Alexander turned on whether the plaintiffs had put forward sufficient evidence that the legislature drew district lines based on race, rather than partisanship. In finding that racial considerations predominated, the district court relied on expert testimony of Dr. Jordan Ragusa. The Supreme Court conducted a close analysis of Dr. Ragusa’s report and concluded that “his analysis has at least two serious defects. First, he failed to account for two key mapmaking factors: contiguity and compactness. Second, he used an inferior method of measuring a precinct’s partisan leanings.”
Can Claude figure this out? I downloaded Dr. Ragusa’s expert report, inputted it into Claude, and asked Claude to identify methodological errors. I didn’t give Claude any hints, and of course the report itself doesn’t flag methodological errors. Here’s what Claude came up with:

This is a stellar answer that addresses the majority’s first concern about the “two key mapmaking factors: contiguity and compactness.” Again, I didn’t give Claude any help. I just inputted the expert report and Claude … figured it out, just like that.
What about the majority’s second concern? The majority elaborates as follows:
Dr. Ragusa’s report also carries less weight because of how he measured a precinct’s partisan leanings. Using the results of the 2020 Presidential election, Dr. Ragusa measured partisan tilt by looking at the total votes cast for President Biden, not the net votes for President Biden. This method fails to account for the fact that voter turnout may vary significantly from precinct to precinct, and therefore a precinct in which a candidate gets a large number of votes may also be a precinct in which the candidate fails to win a majority. …
Dr. Ragusa’s model considers only the total number of Biden votes in its partisanship analysis. J. S. A. 502a. But legislators aiming to make District 1 a relatively safe Republican seat would be foolish to exclude Precinct 2 merely because it has more Democratic votes than Precinct 1. Instead, they would look at the net Democratic votes and would thus remove Precinct 1, not Precinct 2. Although the use of total votes may be a statistically permissible measure of partisan lean, it is undoubtedly preferable for an expert report to rely on net votes when measuring a district’s partisan lean.
As Justice Kagan observes in her dissent, the state didn’t make this argument in its brief. But with a very gentle suggestion, Claude identifies the issue:

Switching gears, suppose you’re a voting-rights lawyer trying to come up with a better way of disentangling race from partisanship. Can Claude offer any useful suggestions on how to do that?
There’s a glitch here—Claude is right that there were numerous white Democrats in South Carolina in the 1960s and 1970s, but it wasn’t the case that “African Americans largely voted Republican” in that era. I also think Claude gets a bit confused at the end of that first paragraph. But this is still outstanding work. Both of these suggestions are, indeed, creative ways of disentangling race from partisanship that Claude pulled out of nowhere.
One more. Turning from fact to law, I asked Claude to suggest two legal standards that would minimize the risk of racial considerations factoring into redistricting. Once again, I’m asking for Claude to come up with new legal standards, completely on its own, without the guidance of briefs, case law, or secondary literature. Claude delivers this answer:

Not to sound like a broken record, but this is a magnificent answer. Each of these two legal standards would, indeed, accomplish the task of ensuring that race does not influence district lines. It’s simply incredible that Claude can do this.
Humans vs. AI
Claude is clearly capable of adjudicating complex cases. But let’s bracket the question of whether AI should be permitted to be a judge and ask an easier question: is AI capable of serving as a law clerk?
In my view, in accuracy and creativity, Claude’s answers are at or above the level of a human Supreme Court clerk. Not only is Claude able to make sensible recommendations and draft judicial opinions, but Claude effortlessly does things like generate novel legal standards and spot methodological errors in expert testimony. Claude does occasionally make mistakes, but humans do too.
And then there’s the efficiency issue. Claude generated all of these answers in one minute or less. Let’s say it takes Claude 60 seconds to read briefs and prepare a draft judicial opinion (which is probably an over-estimate). How long would it take for a human to do the same thing? Maybe 300,000 seconds (about three and a half days)? Of course, a human clerk wouldn’t be working during that entire period—humans have to eat and sleep—but one of AI’s advantages is that it doesn’t get tired. So Claude works at least 5,000 times faster than humans do, while producing work of similar or better quality.
The future is now.
AI is also rapidly improving. New AIs are currently under development that are expected to be significant improvements on today’s state-of-the-art. Also, recall that Claude hasn’t been fine-tuned or trained on any case law. It’s a general-purpose AI. If we taught Claude the entire corpus of American case law, which could be done easily, its legal ability would improve significantly.

I’m not counting O’Connor-Ratliff v. Garnier, in which the Court remanded for further consideration in light of Lindke v. Freed.
For most cases, I uploaded the merits briefs and nothing else. In a couple of cases, I felt it was necessary for Claude to read the Solicitor General’s amicus brief or some key case law in order to make an informed decision, so I uploaded those materials as well. But I never gave Claude any hints.
Like all of Prof. Unikowsky's posts this one is very well written, has outstanding analysis and makes a significant contribution to the discussion of the topic. However it has a fatal flaw.
That flaw is that the post conflates the 'correct' with the 'right' opinion. Of course there is no 'right' or 'correct' opinion. The AI does generate the opinions close to the Court's actual ones but a good case can be made that this Court in its ideologically driven decisions does not often make the 'right' or 'correct' opinion.
What the AI is doing is forecasting the Court's opinion, something that any well informed intelligent legal scholar can do with about as much accuracy as any AI. Prof. Unikowsky should not be as amazed as he is, no more than when the National Weather Service with its banks of computers, its models and probably some AI thrown in gets a weather forecast correct. This is not created intelligence, it is a parlor trick.
I think your methodology has thrown (at least some portions of) this a bit off, unfortunately.
In the section discussing the expert report, you write: "Can Claude figure this out? I downloaded Dr. Ragusa’s expert report, inputted it into Claude, and asked Claude to identify methodological errors. ***I didn’t give Claude any hints,*** and of course the report itself doesn’t flag methodological errors." (emphasis added)
But I'm pretty sure you did this in the same chat where you fed Claude the briefs, which of course *do* identify (alleged) methodological errors. In the middle of Claude's response, there's a reference to "Br. 21." And looking at p. 21 of South Carolina's merits brief, it identifies the precise issues Claude "discovers" here; in fact Claude is basically just regurgitating/restating that portion of the brief.
Quoting now the relevant section of p. 21:
<Dr. Ragusa used a “county envelope” methodology purporting to analyze the VTDs included in or excluded from each district. He assumed that every VTD in a county contained at least partially in a district was available to be included in the district— regardless of the VTD’s location or proximity to the district line. JSA.503a; JA.191. Dr. Ragusa concluded that “race was an important factor” in District 1. JSA.509a. Dr. Ragusa’s model, however, ignored contiguity, compactness, core preservation, avoiding political subdivision splits, and preserving communities of interest, and he admitted that he could not “authoritatively speak to” “[i]ntent.” JA.197; JSA.501a-507a. Rather, all he purported to “speak to is effects,” specifically that “race was an effect in the design of” the Enacted Plan. JA.197. In addition to District 1, his model concluded that race was a “significant factor” in Districts 3 and 6, which Appellees did not challenge, and Districts 2 and 5, where the panel rejected Appellees’ challenges. JSA.507a-513a.>